Redis 网络模型:从"排队等餐"到"智能管家"的进化史
Redis 为什么这么快?除了内存存储,还有一个关键因素:网络模型。今天我们就用生活化的例子,来理解 Redis 网络模型的演进过程,看看它是如何从"排队等餐"进化到"智能管家"的。
核心问题:为什么 Redis 选择单线程模型?为什么新版本引入多线程,但命令执行仍然是单线程?这背后到底发生了什么?
IO 模型演进概览
在深入了解之前,让我们先看看 IO 模型的演进路径:
最原始模式:一线程一连接
忙轮询:虽然不阻塞,但 CPU 空转
Redis 的选择:一个线程监控多个 Socket
epoll (Linux) / kqueue (BSD) 实现事件驱动。
Redis 借此实现了单线程处理数万并发,简单且高效。
半异步:内核通知,应用处理
终极形态:内核全包圆
开篇:为什么 Redis 这么快?
想象一下,你开了一家餐厅:
传统餐厅(多线程模型):
- 每个顾客配一个服务员
- 100 个顾客需要 100 个服务员
- 成本高、管理复杂,服务员之间还要协调工作
Redis 餐厅(单线程模型):
- 只有一个超级服务员
- 但这个服务员有"超能力"——可以同时服务成千上万的顾客
- 成本低、管理简单,不会出现"多个服务员抢着服务一桌"的情况
这个"超能力"就是 IO 多路复用(epoll),它让 Redis 用一个线程就能高效处理大量网络连接。
为什么 Redis 6.0 引入多线程,但核心还是单线程?
就像餐厅增加了"传菜员":
- 主厨(单线程):还是一个人,负责"做菜"(执行 Redis 命令)
- 传菜员(多线程):多人负责"传菜"(网络 IO、解析命令)
为什么这样设计?我们后面会详细解释。
基础概念:先理解"厨房"和"餐厅"
在深入 IO 模型之前,我们需要先理解两个基础概念。
内核空间 vs 用户空间:餐厅的"厨房"和"大厅"
想象一下餐厅的布局:
内核空间(厨房):
- 只有厨师能进,普通顾客不能进
- 这里处理"危险操作":切菜、用火、操作设备
- 如果顾客乱动,整个餐厅都可能出问题
用户空间(大厅):
- 顾客可以自由活动,点餐、用餐、聊天
- 这里是应用程序运行的地方
- 相对安全,出错不会影响整个系统
为什么分开?
就像餐厅不允许顾客进厨房一样,操作系统不允许应用程序直接操作硬件。这就像一道"安全门",防止程序出错导致整个系统崩溃。
缓冲区机制:传菜窗口
数据在"厨房"和"大厅"之间传递,需要一个"传菜窗口"(缓冲区):
- 写数据:把数据从用户空间(大厅)拷贝到内核空间(厨房),然后写入设备
- 读数据:从设备读取数据到内核空间(厨房),然后拷贝到用户空间(大厅)
这个过程涉及两次拷贝,这也是为什么 IO 操作比较慢的原因之一。
文件描述符(FD):餐厅的"订单号"
生活类比:
当你去餐厅点餐时,服务员会给你一个"订单号"。通过这个订单号,你可以:
- 追踪你的餐点状态
- 知道什么时候可以取餐
- 避免搞混不同的订单
技术解释:
在 Linux 系统中,每个打开的文件、每个网络连接,都有一个文件描述符(File Descriptor,简称 FD)。它是一个从 0 开始递增的整数,就像订单号一样。
- 打开一个文件,系统返回一个 FD(比如 3)
- 建立一个网络连接,系统返回一个 FD(比如 4)
- Redis 需要同时处理很多连接,每个连接都有一个 FD
为什么重要?
Redis 要处理大量客户端连接,就需要管理大量的 FD。IO 多路复用就是用一个线程来"监听"这些 FD,看哪个有数据可以处理。
五大 IO 模型:从"排队等餐"到"智能管家"
IO 模型经历了五次进化,让我们用生活场景来理解每一种。
阻塞 IO:最原始的"排队等餐"
生活场景:银行排队办业务
你取号后,必须一直站在队伍里等:
- 不能离开
- 不能做其他事
- 不能玩手机(因为要盯着队伍)
- 轮到你才能办业务
这就是阻塞 IO:应用程序发起请求后,必须一直等待,直到数据准备好并复制完成,才能继续执行。
技术原理:
应用程序发起 read 请求
↓
内核准备数据(阻塞等待)
↓
数据复制到用户空间(阻塞等待)
↓
应用程序继续执行
整个过程,应用程序的线程都被"阻塞"了,就像你一直站在队伍里。
问题:
如果有很多客户,需要很多窗口(线程):
- 1000 个连接需要 1000 个线程
- 每个线程都要占用内存(每个线程约 1-2MB)
- 线程切换的开销也很大
- 成本高,效率低
在高并发场景下,这种方式完全不可行。
非阻塞 IO:可以"四处逛逛"的等待
生活场景:快餐店的"呼叫器"
你点餐后,拿到一个呼叫器:
- 可以四处逛逛,不用一直站着等
- 可以看手机、聊天
- 但你需要不停地看呼叫器,看餐好了没
- 餐好了,你还要自己走过去取(这个阶段还是要等)
这就是非阻塞 IO:发起请求后立即返回(不阻塞),但需要不断轮询(问:好了没?好了没?)。
技术原理:
应用程序发起 read 请求
↓
立即返回(不阻塞)
↓
应用程序不断轮询:"数据好了没?"
↓
数据准备好了
↓
数据复制到用户空间(阻塞等待)← 这里还是要等!
↓
应用程序继续执行
问题:
- CPU 空转:就像你不停地看呼叫器,很累但效率不高
- 数据复制阶段仍阻塞:数据准备好后,复制数据到用户空间时还是要等待
- 浪费资源:大部分时间都在"空等",没有实际工作
这种方式虽然不阻塞,但效率并没有提高多少。
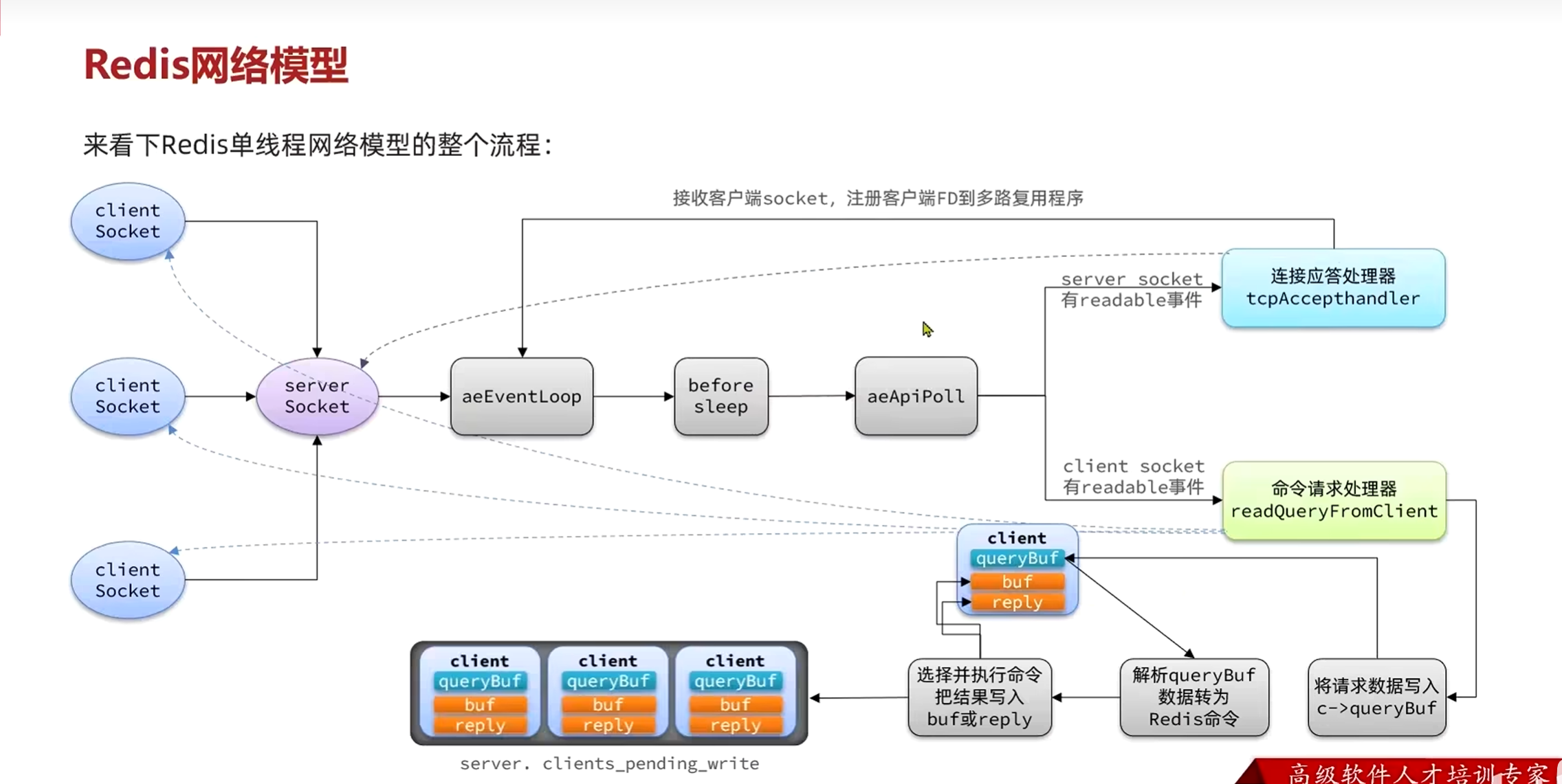
IO 多路复用:一个"超级服务员"同时服务多桌
生活场景:高级餐厅的"智能服务员"
想象一个高级餐厅,有一个超级服务员:
- 他可以同时照看 10 桌、100 桌甚至 1000 桌客人
- 他有一个"智能平板"(epoll),显示每桌的状态
- 哪桌需要服务,平板会主动提醒(事件通知)
- 服务员不需要挨个问"需要什么吗?"
这就是IO 多路复用:用一个线程监听多个 FD,当某个 FD 有数据时,主动通知应用程序。
技术原理:
应用程序注册要监听的 FD
↓
调用 select/poll/epoll(阻塞等待,但只阻塞一次)
↓
内核监控所有 FD
↓
某个 FD 有数据了(事件通知)
↓
应用程序处理这个 FD 的数据(数据复制时阻塞)
↓
继续监听下一个事件
关键优势:只阻塞一次,就能知道多个 FD 中哪些有数据。
三种实现方式:
select:最原始的"平板"
生活类比:
- 一个只能显示 1024 桌的平板
- 每次都要把所有桌子的信息都看一遍
- 每次都要把信息从"厨房"传到"大厅"(用户空间和内核空间拷贝)
技术问题:
- FD 数量限制:最多只能监听 1024 个 FD
- 需要遍历所有 FD:即使只有 1 个 FD 有数据,也要检查所有 FD
- 需要拷贝 fd_set:每次调用都要把 fd_set 从用户空间拷贝到内核空间,返回时再拷贝回来
在高并发场景下,这些开销是巨大的。
poll:改进的"平板"
生活类比:
- 平板可以显示无限桌(没有 1024 的限制)
- 但还是每次都要看所有桌子(遍历所有 FD)
改进:
- 解决了 FD 数量限制的问题(使用链表存储,理论上无上限)
问题:
- 还是要遍历所有 FD,效率不高
- 仍然需要拷贝 pollfd 数组
虽然比 select 好一点,但在高并发场景下性能仍然不够理想。
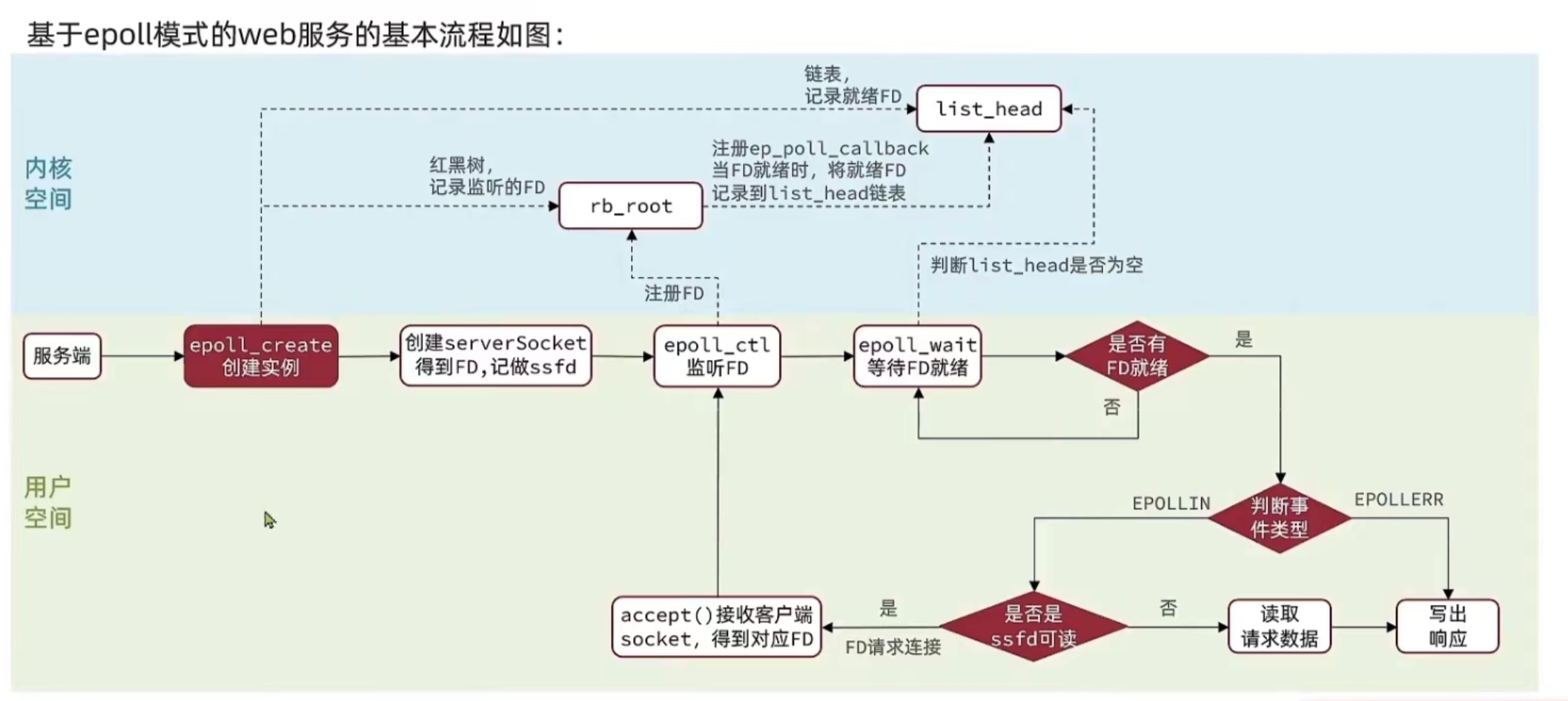
epoll:最智能的"平板"(Redis 的选择)
生活类比:
- 智能平板,只显示"需要服务的桌子"
- 不需要遍历所有桌子
- 桌子状态变化时,平板主动提醒
工作原理:
epoll 在内核中维护两个数据结构:
-
红黑树:记录所有要监听的 FD
- 查找、添加、删除的效率都是 O(log n)
- 就像智能平板的"桌子列表"
-
就绪链表:只记录"需要服务的桌子"
- 当某个 FD 有数据时,内核把它添加到这个链表
- 就像平板只显示"需要服务的桌子"
工作流程:
1. epoll_create:创建 epoll 实例(创建智能平板)
↓
2. epoll_ctl:添加要监听的 FD(把桌子加入平板)
↓
3. epoll_wait:等待事件(平板主动提醒哪些桌子需要服务)
↓
4. 处理就绪的 FD(服务员去服务这些桌子)
核心优势:
- 不需要遍历所有 FD:只返回就绪的 FD
- 不需要重复拷贝:FD 只需添加一次到内核空间
- 性能不受 FD 数量影响:即使监听 10 万个 FD,性能也不会明显下降
- 事件驱动:内核主动通知,不需要轮询
这就是为什么 Redis 选择 epoll 的原因!
信号驱动 IO:餐厅的"广播通知"
生活场景:电影院散场
你买票后,可以自由活动:
- 可以逛街、吃饭、玩手机(不阻塞)
- 电影结束后,广播通知所有观众(信号通知)
- 你听到广播后,自己走过去(数据复制阶段仍阻塞)
这就是信号驱动 IO:注册信号处理函数,内核数据准备好时发送信号通知,用户进程收到信号后自己去读取数据。
技术原理:
应用程序注册信号处理函数(SIGIO)
↓
发起 read 请求,立即返回(不阻塞)
↓
应用程序可以做其他事情
↓
内核数据准备好了,发送 SIGIO 信号
↓
应用程序收到信号,去读取数据(数据复制时阻塞)← 这里还是要等!
优缺点:
- 优点:等待阶段不阻塞,可以做其他事情
- 缺点:
- 信号处理复杂
- 信号可能丢失(就像广播可能听不清)
- 数据复制阶段还是要阻塞等待
- 不适合高并发场景
为什么 Redis 不用?
信号处理太复杂,而且 epoll 已经足够好了。就像餐厅有智能平板就够用,不需要广播系统。
异步 IO:最完美的"代购服务"
生活场景:代购服务
你下单后,完全不用管:
- 可以工作、睡觉、做任何事(完全不阻塞)
- 代购员会:
- 去采购(数据准备)
- 送到你家(数据复制)
- 打电话通知你(回调通知)
- 整个过程你完全不用等待
这就是异步 IO:发起请求后立即返回,内核完成数据准备和数据复制,然后通过回调通知应用程序。
技术原理:
应用程序发起 aio_read 请求
↓
立即返回(不阻塞)
↓
应用程序可以做任何事(完全不阻塞)
↓
内核完成:
1. 数据准备
2. 数据复制到用户空间
↓
内核通过回调函数通知应用程序
↓
应用程序处理数据
与信号驱动 IO 的区别:
- 信号驱动 IO:数据准备好后通知你,但你还要自己去取(复制阶段阻塞)
- 异步 IO:数据准备好并送到你手上后,才通知你(完全非阻塞)
这是唯一一个完全非阻塞的 IO 模型。
Linux 异步 IO 的现状:
Linux 原生 AIO(libaio)有很多限制:
- 只支持直接 IO(O_DIRECT),不支持缓冲 IO
- 只支持磁盘 IO,对网络 IO 支持不好
- 性能一般,不如 epoll
所以很多系统用 epoll + 线程池来模拟异步 IO 的效果:
- Node.js:用 libuv(基于 epoll)实现异步 IO
- Nginx:用 epoll + 事件驱动实现高并发
为什么 Redis 不用异步 IO?
- Linux AIO 不完善:对网络 IO 支持不好
- epoll 已经足够好:一个线程可以处理数万个连接
- 复杂度 vs 收益:异步 IO 带来的提升有限,但复杂度大大增加
- 跨平台兼容性:Windows 和 Linux 的 AIO 实现不同
就像餐厅有智能平板就够用了,不需要完美的代购服务(而且这个服务还不完善)。
五种模型对比:一张表格看懂所有
让我们用一个表格来总结五种 IO 模型的特点:
| 模型 | 生活类比 | 等待阶段 | 数据复制阶段 | 性能 | 复杂度 | 实际应用 |
|---|---|---|---|---|---|---|
| 阻塞 IO | 银行排队 | 阻塞等待 | 阻塞等待 | 低 | 简单 | 简单场景 |
| 非阻塞 IO | 快餐店呼叫器 | 不阻塞(但忙等) | 阻塞等待 | 低 | 中等 | 很少用 |
| IO 多路复用 | 智能服务员 | 不阻塞(事件通知) | 阻塞等待 | 高 | 中等 | Redis、Nginx |
| 信号驱动 IO | 电影院广播 | 不阻塞(信号通知) | 阻塞等待 | 中 | 复杂 | 很少用 |
| 异步 IO | 代购服务 | 不阻塞 | 不阻塞 | 高 | 复杂 | Windows IOCP、Node.js(模拟) |
关键理解:
- 前四种模型,数据复制阶段都要阻塞:只有异步 IO 是完全非阻塞的
- 但 Linux 的异步 IO 不完善:所以 Redis 选择 epoll
- epoll 是性价比最高的选择:性能好、复杂度适中、跨平台
Redis 的选择:为什么是 epoll?
生活场景:Redis 就像一家"极致效率"的餐厅
Redis 的设计哲学是:简单、高效、可靠。epoll 完美契合这个理念。
为什么选择 epoll?
epoll 是事件驱动的,只处理’活跃’连接
无需复杂的异步回调地狱,逻辑线性清晰
Redis 封装了简单的事件驱动库 ae.c
epoll,macOS/BSD 用 kqueue,老旧系统降级用 select。
避免了多线程的上下文切换和锁竞争
为什么不选异步 IO?
虽然异步 IO 理论上是最完美的,但:
- Linux AIO 不完善:对网络 IO 支持不好,只支持磁盘 IO
- epoll 已经足够好:一个线程处理数万连接,性能已经足够
- 复杂度 vs 收益:异步 IO 带来的提升有限,但复杂度大大增加
- 单线程模型的优势:Redis 的单线程模型已经避免了锁的复杂性,异步 IO 的复杂度会破坏这个优势
就像餐厅有智能平板就够用了,不需要完美的代购服务(而且这个服务还不完善)。
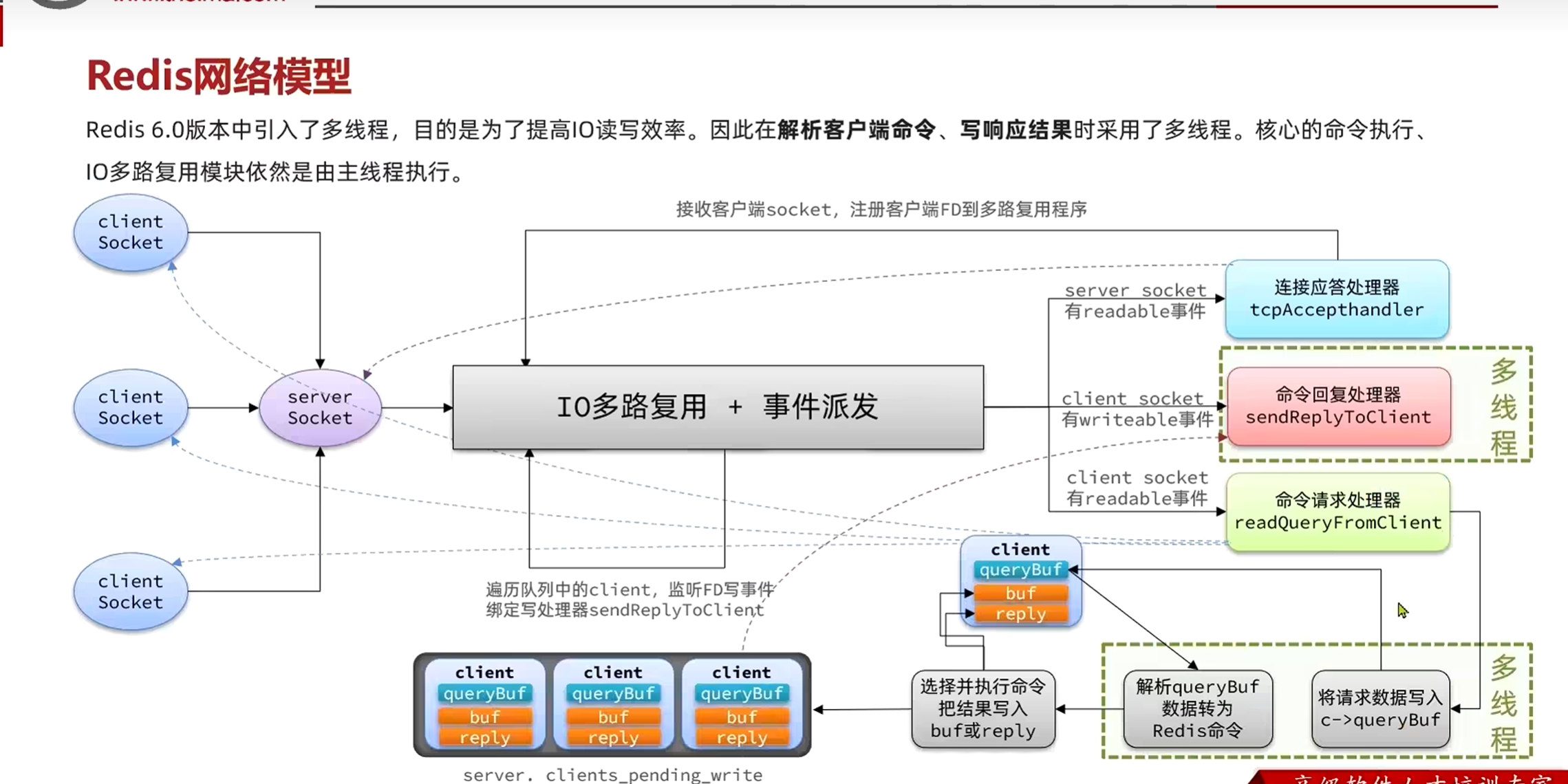
Redis 6.0+ 多线程:增加"传菜员"
生活场景:餐厅增加了"传菜员"
Redis 6.0 之前,一切都是单线程:
- 一个服务员(主线程)负责所有工作:接收订单、传菜、做菜、上菜
Redis 6.0 之后,引入了多线程 IO:
- 主厨(主线程):还是一个人,负责"做菜"(执行 Redis 命令)
- 传菜员(IO 线程):多人负责"传菜"(网络 IO、解析命令)
为什么这样设计?
做菜很快(命令执行):
- Redis 命令执行是内存操作,非常快(微秒级别)
- 如果多线程执行命令,需要加锁,反而变慢
- 就像多个厨师做一道菜,反而会互相干扰
传菜很慢(网络 IO):
- 网络 IO 和解析命令比较慢(毫秒级别)
- 多线程可以并发处理,提升效率
- 就像多个传菜员可以同时传多道菜
多线程处理什么?
Redis 6.0+ 的多线程主要处理:
- 网络读取:从网络读取客户端发送的数据
- 命令解析:解析 Redis 命令协议
- 命令执行:仍然是单线程(主线程执行)
工作流程:
Socket 数据包进入内核缓冲区
主线程分配 Socket 任务,多线程并行从网卡读取数据
将原始二进制流解析为 Redis 指令 (RESP 协议)
核心步骤:单线程串行执行,确保绝对原子性
IO 线程将计算结果并行写回 Socket 缓冲区
客户端接收结果,整个请求周期闭环
性能提升
在高并发场景下,IO 不再是瓶颈:
- 原来:主线程要等待网络 IO 完成
- 现在:IO 线程并发处理,主线程可以更快地执行命令
- 就像餐厅有了传菜员,主厨可以专心做菜,效率更高
但要注意:
- 命令执行仍然是单线程,保证了 Redis 的简单性和可靠性
- 多线程只在 IO 层面,避免了锁的复杂性
总结:从"排队等餐"到"智能管家"
IO 模型演进历程
像传统的银行柜台:一个窗口只能服务一个客户
不用死等,但要反复询问:‘好了吗?好了吗?’
Redis 的核心:一个’总管’监听所有连接
内核通知,但处理逻辑过于碎片化
理想的’全托管’模式,但 Linux 生态尚在追赶
Redis 的选择
- 网络模型:epoll(IO 多路复用)
- 命令执行:单线程(简单、可靠、性能好)
- IO 处理:多线程(Redis 6.0+,提升 IO 性能)
核心优势
- 简单:单线程执行命令,避免了锁的复杂性
- 高效:epoll + 单线程,性能达到极致
- 可靠:单线程模型,避免了多线程的并发问题
未来展望
Redis 可能会继续优化网络模型,但核心设计理念不会变:
- 单线程执行命令:保证简单性和可靠性
- epoll 网络模型:保证高性能
- 多线程 IO:在需要时提升 IO 性能
参考资料
- 深底解析redis网络模型,到底什么是epoll? - 腾讯云开发者社区
- Redis原理之网络模型笔记 - 阿里云开发者社区
- Redis 官方文档
希望通过这篇文章,你能理解 Redis 网络模型的演进过程,以及为什么 Redis 选择 epoll 作为网络模型。记住:简单、高效、可靠,这就是 Redis 的设计哲学。